안녕하세요, 메이아이의 Lead Researcher 박진우입니다.
이 글은 메이아이의 첫 논문 리뷰 포스트입니다. 메이아이에서 처음으로 여러분들께 소개해드리고자 하는 논문은 2019년 ICLR에 제출된 <Rethinking the Value of Network Pruning>입니다. 동일 년도 ICLR에서 Best Paper로 선정된 <Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks>와 같이 실험 방법이나 원리 자체는 비교적 단순하면서도, 뉴럴 네트워크 모델의 근본적인 학습 원리에 대해 질문을 던지고 있는 꽤나 유명한 논문입니다.
개인적인 느낌이지만 이 논문 이후로 ‘rethinking’이라는 단어로 비슷하게 시작하는 논문 제목들이 좀 더 많이 생겨나지 않았나 싶을 정도로요. 물론 이런 주관적인 지표 말고도, 비교적 최근이라 할 수 있는 2019년도에 출간되었는데도 불구하고, 벌써 328회나 인용되었다는 점에서 그 점을 확인하실 수 있습니다.
 Eric-mingjie
Eric-mingjie이 논문은 Network Pruning에 대해 이야기하고 있습니다. Network Pruning은 각자 하시는 분야에 따라 익숙하신 분들도 있고, 아예 모르셨던 분들도 있을 텐데요. 보통 딥러닝 모델의 저장 용량을 줄이거나 혹은 상황에 따라 모델의 추론 속도를 더 빠르게 하기 위해 사용됩니다. 어떻게 보면 딥러닝 모델의 최적 구조를 탐색하기 위한 NAS(Neural Architecture Search)와 궤를 같이 한다고 볼 수 있겠네요. 그 외에도 근본적인 딥러닝 모델 구조의 원리 등을 해석하기 위하는 것 등과 같이 좀 더 연구적인 측면의 접근들도 이뤄지긴 합니다.
메이아이에서는 연구적 측면보다는 좀 더 실용적 측면에서 Network Pruning에 대해 관심을 가지고 있습니다. 비록 최근까지 정확도 대비 real-time으로 볼 수 있는 여러 detector들이 연구되고 또 제시되고 있지만, 아직까지는 속도 대비 정확도가 그리 만족스럽지 않거나 정확도는 뛰어난데 속도가 조금 느린 듯싶은 모델들이 대부분입니다. 또한 저희가 제공하는 오프라인 공간 분석 솔루션에는 Object detection 이외의 많은 부가적인 모델들이 직렬로 연결되어 있기 때문에, 아무리 detector가 real-time을 만족한다고 해도 전체 서비스가 real-time으로 돌아간다는 보장을 할 수 없습니다. 사실 생각해 보면 저희가 직접 설계해서 학습하지 않는 한, 외부의 연구들을 참조한다고 원하는 속도-정확도 조건에 딱 맞는 모델을 찾을 수 있을 리가 만무하긴 합니다.
이런 상황에서 Network Pruning은 꽤나 간단하면서도 강력합니다. 특히, 이미 학습되어 사용되고 있는 모델이 있으므로 더더욱 쉽게 Pruning 쪽에 눈길이 갈 수밖에 없습니다. 일단 Pruning을 사용하지 않고, 우리한테 맞는 네트워크 구조를 처음부터 새로 찾는다고 생각해 본다면 어디서부터 시작해야 할지 벌써부터 막막합니다. 어찌어찌해서 테스트할 만한 구조를 설계해도, 학습을 처음부터 다시 해야 합니다. 학습이 끝나면 만족할 만한 성능이 나왔는지 체크해야 하는데, 긍정적이라면 괜찮지만 만족할만하지 않다면 구조 설계를 다시 하고, 학습을 또 새로 처음부터 해야 합니다. 최대한 태스크에 들어가는 자원을 아껴서 다른 연구도 하고 싶어 하는 저희 입장에서는, 정말 지옥도 이런 지옥이 없습니다.
하지만 Pruning을 사용한다면 어떨까요? 저희는 현재 사용하고 있는 모델이 있으므로, 해당 모델의 parameter를 전부 불러온 다음 간단하게 가중치들의 중요도를 산정합니다. 그리고, 해당 가중치들을 바탕으로 일정 중요도 이하, 혹은 하위 몇 % 이하의 중요도 수치를 가진 가중치들을 모델 그래프에서 제거한 뒤, fine-tuning을 진행합니다. 이렇게 되면 위에서 말씀드렸던, 처음부터 모델 구조를 찾는 것과 비교하여 몇 가지 장점이 있습니다.
첫 번째로는, 재활용이 가능합니다. Pruning의 경우는 pretrained model에서 일정 가중치들을 잘라서 쓰는 것이기 때문에, pretrained model만 가지고 있으면 얼마든지 해당 과정을 진행할 수 있습니다. 또한 기존 방법이 좀 더 잘 될 것이라는 가설(채널 수를 임의로 조정한다든지, 특정 conv 모듈로 대체한다든지 등)을 기반으로 이루어진다면, pruning은 좀 더 근거를 가지고 경량화를 진행할 수 있습니다. 물론 그렇다 하더라도, 결국은 모델 구조를 찾고 학습을 다시 진행하는 구조는 동일한 것이 아니냐고 말할 수도 있습니다. 하지만, pruning은 기존과 달리 이전에 한 번 학습되었던 가중치를 초깃값으로 두고 fine-tuning을 진행하는 것이고, 모델을 새로 설계해서 학습하면 기껏 해 봐야 imagenet pretrain 모델을 사용하는 등 시작점이 다릅니다. 이 점 덕분에 보통은 pruning의 fine-tuning 방법이 훨씬 빨리 수렴하는 모습을 보이며, 이는 해당 연구에 소모되는 자원이 훨씬 적다는 것을 의미합니다.
다만, 마지막 사항에 대해서는 좀 더 조심해서 생각해 볼 필요가 있습니다. 물론 기존 네트워크에서 해당 가중치의 중요도가 높아서 남겨둔 것이라고는 하지만, 결과적으로 해당 가중치의 값이 실제 이용되는 건 ‘기존과 다른 구조’의 모델입니다. 여러분들도 잘 알고 계시듯, 보통 가중치 초기화를 진행하는 기법은 해당 모델의 구조(연결된 뉴런의 수 등)와 관련이 있습니다. 그렇다면, 원래 잘 동작하던 가중치의 값을 그대로 초깃값에 쓰는 게 정말로 맞는 걸까요? 해당 가중치가 원래 가중치가 하던 역할과 의미적으로 얼마나 비슷할까요? 즉, pruning 이후 fine-tuning 시 네트워크 초기화를 어떻게 해야 할까요? 바로 이 논문에서 주로 이야기하고자 하는 점이 바로 이 점입니다.
따라서 이번 포스트에서는 이 <Rethinking the Value of Network Pruning>을 리뷰하면서, Network Pruning이라는 분야에 대한 전반적인 내용을 살펴보고, 기존에 어떤 방법들이 있었는지, 마지막으로 이 논문에서는 어떻게 이야기하고 있는지 두루두루 살펴보는 시간을 가지려 합니다.
사실 Network Pruning 자체는 꽤나 예전부터 있던 연구 주제라, 보통 연구의 시간 순으로 보자면 이 논문보다 Network Pruning 분야에 입문하기 좋은 논문들이 있습니다. 예를 들면 <Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding(Han et al., 2015)>같은 논문입니다.
하지만 <Rethinking the Value of Network Pruning>을 선택한 이유는 해당 논문이 비교적 최근 논문이며, 자신의 이론을 설명하기 위해 기존에 있었던 Pruning 방법들을 분류 후 분석하였고, 그 과정에서 기존에 어떠한 방법들이 있었는지 파악할 수 있기 때문입니다. 또한 마지막으로 이 논문 전에 나왔던 여러 대표적인 Pruning 방법들에 대해 실험을 진행하고 코드를 Github에 올려놓았기 때문에 논문에서 사용된 기존 pruning 방법들을 통일된 양식의 코드로 접할 수 있다는 큰 장점이 있어, 어느 정도의 review paper 못지않게 기존 pruning 방법들을 파악할 수 있기 좋은 논문이라고 생각하여 여러분들과 같이 읽어보고자 합니다.
Network Pruning 논문 리뷰는 두 편의 글로 나누려고 합니다. 이번 글에서는 주로 논문의 도입부와 방법론(Methodology)에 해당하는 pruning 분야에 대한 전반적인 부분을 다루겠습니다. 다음 글에서는 실제 실험에 사용된 pruning 테크닉들을 논문보다 조금 더 자세히 살펴보고, 해당 실험 결과에 대해 논문에서 분석한 내용들을 살펴보는 시간을 갖겠습니다.
Paper Introduction
Network Pruning의 목적은 딥러닝 모델의 특성인 over-paramterization으로 인한 모델 추론 시의 높은 계산 코스트와 높은 memory footprint를 해결하기 위해 제시되었습니다.
사실 앞서 말씀드렸듯, Network Pruning 자체는 1990년대에 처음 제시되었던, 꽤나 역사가 있는 테크닉입니다. 초기 연구인 <Optimal Brain Damage (LeCun et al., 1990)>이라던가, <Optimal Brain Surgeon (Hassibi & Stork, 1993)>이라는 연구들에서는 학습 완료된 뉴럴 네트워크 모델 가중치들의 Hessian을 이용한 ‘saliency’라는 지표를 이론 상으로 도출, 해당 지표를 기준으로 일정 비율의 parameter들을 네트워크 그래프에서 제거해 버린 다음 남은 가중치들만 fine-tuning하는 방법을 제시하고 있습니다. 더 자세한 내용이 더 알고 싶으시다면 직접 논문을 읽으시거나, 혹은 <Pattern Recognition and Machine Learning (Bishop, 2006)>라는 책의 Chap. 5 부분을 참고하시면 될 것 같습니다.
꽤나 길었던 AI winter가 지나고, 다시 찾아온 뉴럴 네트워크의 전성기에 처음 피어난 Network Pruning은 <Learning both weights and connections for efficient neural network(Han et al., NIPS, 2015)>입니다. 해당 논문에서는 학습된 가중치의 magnitude, 즉 절댓값의 크기를 바탕으로 magnitude가 작은 가중치들을 (iterative 하게) prune 하는 방법을 제시하였고, 이어지는 논문 <Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding(Han et al., ICLR 2016)>에서는 이전 논문에서 소개되었던 magnitude based weight pruning에 더하여 Quantization에 더해 Huffman Coding까지 추가하는 방법을 제시합니다.
Deep Compression 이후에는 여러 가지 Pruning 방법이 등장하는데, 예를 들면 <Dynamic Network Surgery for Efficient DNNs(Guo et al., NIPS 2016)>에서는 prune된 가중치들을 splice, 즉 다시 이어주면서 dynamic하게 pruning을 진행해 나가는 알고리즘을 제안합니다. 혹은 <Pruning filters for efficient convnets(Li et al., ICLR 2017)>에서와 같이 기존 pruning이 weight 단위로 잘랐던 것에서 탈피하여 convolution layer의 filter들과 같은 structure 단위의 pruning을 진행하기 시작합니다.
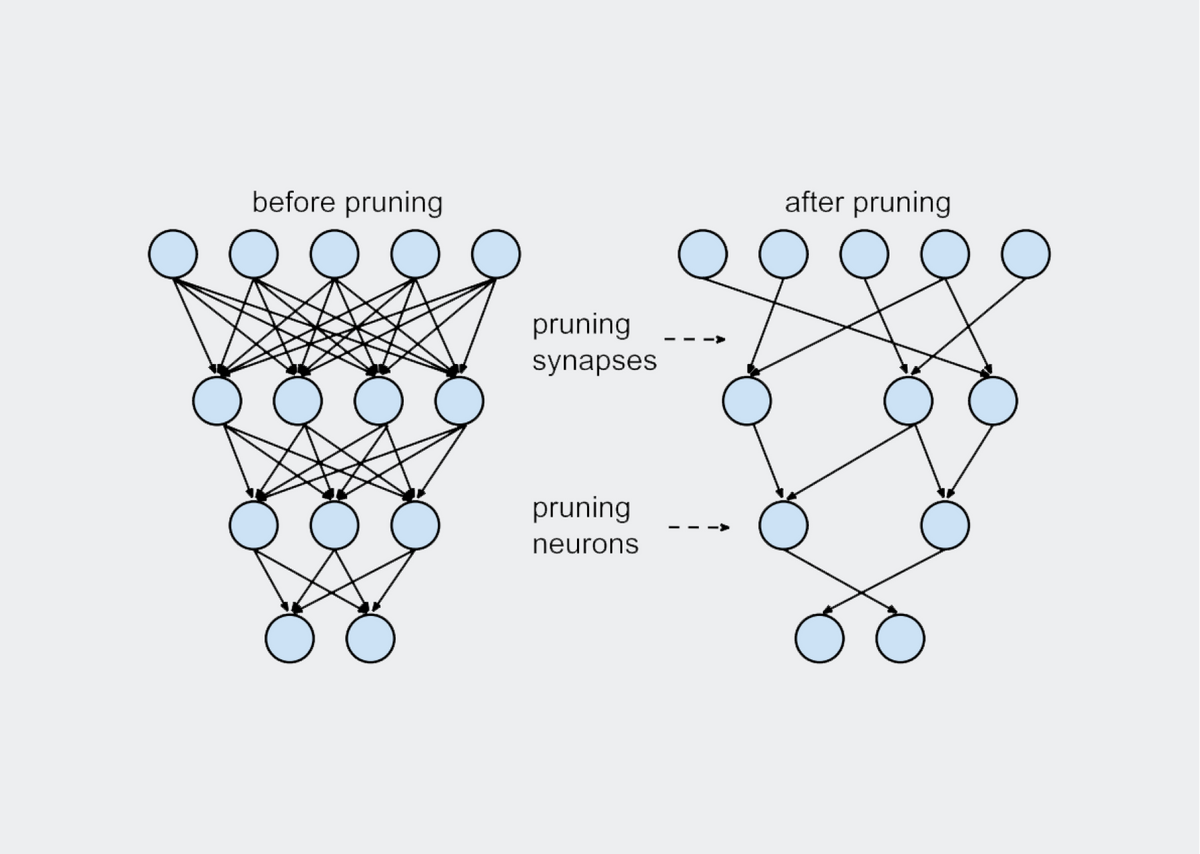
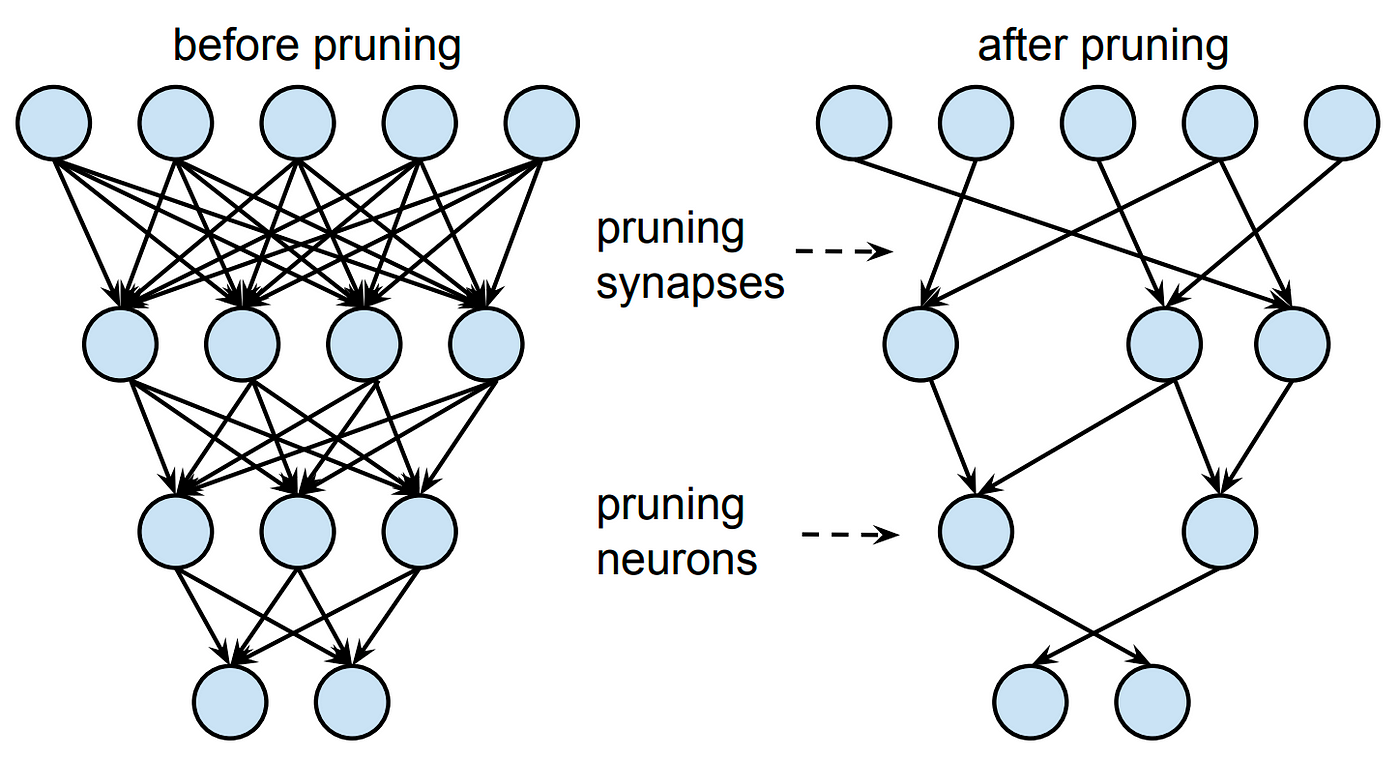
하지만 이렇게 여러 가지 pruning 방법이 제시된 것에 반하여, 본질적으로 pruning의 전체적인 맥락은 동일합니다. 일단 (1) 굉장히 크고 over-parameterized target network을 학습시키고, (2) 어떠한 방식으로든 간에 각 가중치(단위)의 중요도를 산정한 다음 일정 비율을 잘라내고, (3) 가중치를 잘라냄으로써 얻은 정확도 손실을 다시 fine-tuning 과정을 거쳐 복구합니다. 논문에 나와있는 그림으로는 아래와 같습니다.

해당 과정은 굉장히 당연한 것처럼 보이지만, 사실 두 가지의 전제가 숨겨져 있습니다. 첫 번째는 우리는 큰 Target network를 선정한 후 그것을 pruning 한다는 것입니다. 왜 큰 Target Network를 선정하냐고 묻는다면, 당연히 기존의 target network가 클수록 더 정확도가 높기 때문일 것이고, pruning 과정에서 없어지는 잉여의(redundant) 가중치들이 원래 모델에 끼치는 영향이 덜했을 것이라 더 작은 모델에서 자르는 것보다 죄책감 없이 (모델에 영향을 덜 주면서) 자를 수 있을 것이라고 여길 수 있기 때문입니다. 또한 이 점은 기존의 여러 연구들에서, 큰 모델을 자른 것과 작은 모델을 처음부터 학습한 것을 비교했을 때 전자가 더 좋다는 점을 보여주었기 때문에 더 당연하게 받아들여졌습니다.
두 번째 전제는 prune되어 남은 구조와 그 구조가 유지하고 있는 가중치의 값이 둘 다 중요한 의미를 가진다는 점입니다. 다른 의미로, magnitude 기반 prune을 진행한다고 할 때, 어떤 가중치가 2.0의 값을 가지고 있어서 잘리지 않았다고 한다면 그 가중치는 당연히 2.0의 값을 가지고 있었기 때문에 중요하고, 따라서 2.0이란 값은 fine-tuning 과정에도 어떻게든 반영되어야 한다는 점을 당연하게 생각할 수 있습니다.
하지만 이 논문에서는 위의 두 전제에 대해 반론을 제기합니다. 정확히는, 해당 전제들은 structured pruning 방법론들에 대해서는 참이 아닐 수도 있다는 주장을 합니다. 여기서 structured pruning 방법론들이란, 위에서 잠깐 말씀드렸던 filter pruning (channel pruning과 결과 상 동일한)과 같이 channel 이상의 단위로 pruning 여부를 판단하는 방법들입니다.
논문에서는 주로 두 가지 현상에 대해 이야기하고 있습니다. 첫 번째 현상은, predefined network architecture로 structured pruning을 진행한다고 할 때, 해당 target model을 그냥 랜덤 초기화를 진행하여 학습하는 것이 더 좋다는 것입니다. 예를 들어, 기존 resnet18 모델의 모든 채널 수를 2배(resnet18X2)로 늘려서 학습시킨 후, 모든 레이어에서 절반의 filter를 prune하는 방식으로 네트워크를 얻는 것보다 그냥 원래 채널 수를 가진 모델을 학습하는 것이 결과적으로는 정확도가 더 좋다는 것입니다. 아무리 resnet18X2 모델의 pruning 전의 정확도가 더 높다고 하더라도요. 두 번째 현상은, auto-discovered network architecture을 structured pruning을 통해 얻고자 할 때, 얻어진 architecture를 마찬가지로 처음부터 학습하는 것이 fine-tuning과 비슷하거나 더 좋은 정확도를 보인다는 것입니다.

위의 두 현상을 정리하면, 결국 structured pruning 방법들에 대해서 최대한 용량 대비 정확도를 확보하려면 남겨진 가중치 값들을 그대로 가져와서 fine-tuning 하는 것이 아니라, 남겨진 가중치 값들을 무시하고 random initialization (ex. Xavier, He, etc.)을 진행하여 학습해야 한다고 할 수 있습니다. 즉, 우리가 pruning을 통해 얻는 것은 남겨진 ‘구조’이지, ‘구조의 내용물’은 중요하지 않다는 점을 논문에서는 강조하고 있습니다.
잠깐, 그렇다면 unstructured pruning의 경우는 어떨까요? 논문에서는 처음부터 학습(이하 from scratch)하는 방법이 MNIST와 같은 작은 benchmark에서는 structured와 마찬가지로 비슷한 정확도를 보였으나, ImageNet과 같은 large-scale benchmark에서는 원래 알려져 있던 대로 fine-tuning하는 방법이 더 좋은 결과를 보여주었다고 합니다.
물론 structured pruning에서 from scratch 방법이 더 좋았다고 해서 기존 방법이 가치가 없어지는 것은 아닙니다. fine-tuning을 하게 될 때의 가장 큰 장점은 학습 속도로, fine-tuning은 from scratch에 비하면 거의 1/10 정도의 iteration만 수행할 정도로 빠르고, 그렇다고 해서 정확도가 엄청나게 많이 떨어지는 것도 아닙니다. 하지만 딥러닝 모델의 성질을 이해하려 하는 연구자들에게, 해당 성질은 너무나도 흥미로운 것입니다.
위의 두 현상을 통해, 논문에서 주장하는 pruning algorithm에 대한 의견은 다음과 같습니다. 일단 pruning 대상이 되는 첫 모델은 꼭 over-parameterized 될 필요가 없다는 점입니다. 또한 pruning 후 남은 가중치들의 ‘값’ 자체는 그리 optimal 한 것이 아니며, 이는 오히려 bad local minimum으로 유도할 수 있다고 말하고 있습니다. 따라서, 저자들은 다른 시각으로 보면 automatic structured pruning 알고리즘들은 중요한 ‘weight’을 찾는 과정이라기 보다는, 효과적인 network structure을 찾는 과정에 더 가깝다고 해석할 수 있다고 주장하고 있습니다. 즉 filter/channel pruning의 경우는 filter/channel 중 어떤 filter/channel을 자른다는 의미보다는, 단순히 해당 convolution filter의 수를 조절하는 느낌이 더 강하다는 뜻입니다. 이 논문에서는 해당 사실을 바탕으로, Section 5에서의 몇 가지 실험을 통해 효과적인 architecture에 대한 몇 가지 가이드라인을 제시하고 있습니다.
마지막으로, 논문에서는 앞서 잠시 언급되었던 'Lottery Ticket Hypothesis'에 대해 잠시 설명하고 있습니다. Lottery Ticket Hypothesis 자체도 굉장히 큰 주제이기 때문에 자세하게 설명드리기는 힘드나, Lottery Ticket을 찾는 실험이 weight pruning을 진행한 후, 해당 weight의 가장 처음 값, 즉 초깃값을 불러와서 학습시키는 방법을 사용하기 때문에 pruning 후 weight initialization이라는 공통점에서 저자들은 해당 논문과의 연관성을 말하고 있습니다.
Background
해당 Section에서는 기존 Network Pruning 분야에 대해 설명하고 있습니다. 보통 Network Pruning이 연구되는 목적은 위에서도 언급되었듯 자원 활용이 제약된 환경에서 딥러닝 모델을 사용하기 위한 목적이 대다수이며, 보통 모델 용량, 메모리, FLOPs, 전력 소모 측면의 자원이 고려되고 있습니다. 주로 이런 환경은 임베디드 환경, 즉 드론이나 모바일 환경과 관련된 연구를 진행할 때 언급되곤 합니다.
사실 Pruning이 해당 문제를 해결할 수 있는 유일한 환경은 아닙니다. 가중치 행렬을 더 작은 크기의 행렬로 취급 가능한 Low-rank approximation이라던가, 가중치 값의 경우의 수를 대폭 감소시킨 가중치 Quantization, 큰 모델의 logit 등으로 작은 모델을 학습시키는 Knowledge Distillation 등도 있습니다만, 언급만 하고 지나가겠습니다.
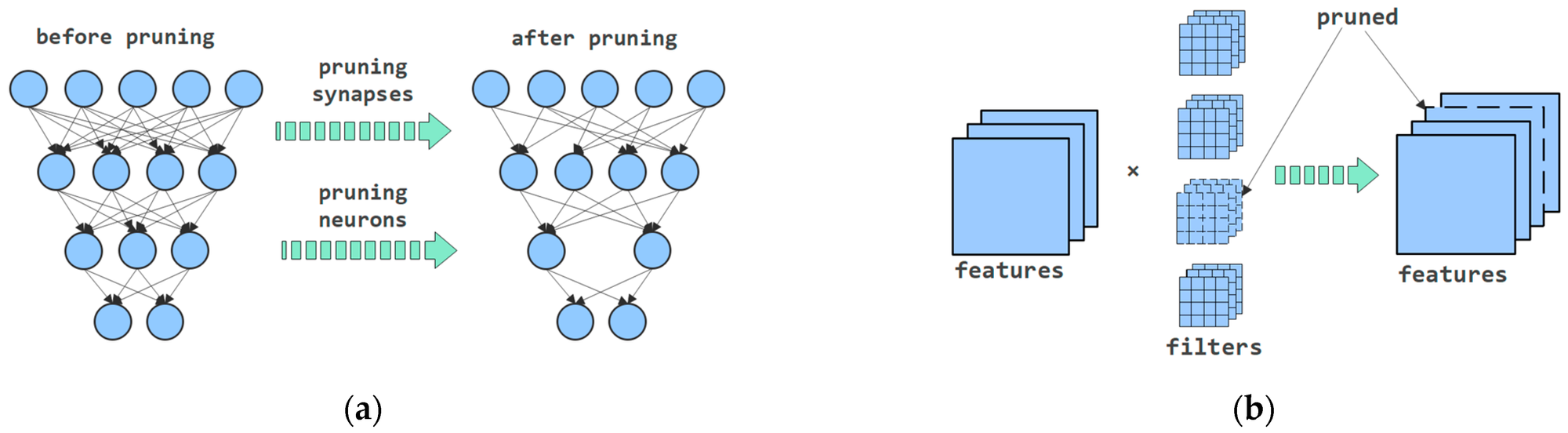
Network Pruning은 가장 크게 두 가지 종류로 나눌 수 있습니다. 바로 위에서도 언급되었던 weight pruning (unstructured pruning)과 structured pruning입니다. weight pruning은 Network Pruning의 시초인 Optimal Brain Damage부터 시작해서 Deep Compression까지 pruning 분야에서 전통적으로 다뤄지고 있는 부분입니다. 공통적으로, weight pruning은 각각의 weight parameter element 하나마다 중요도를 설정하고, 해당 중요도가 낮은 순서대로 prune하는 방법으로 이루어집니다. 일반적으로, 해당 중요도는 학습이 전부 이루어진 후의 모델에서 공정을 시작하지만, 예외도 있습니다. <Sparse Variational Dropout (SVD, Molchanov et al., 2017)>이나 <L0-norm regularization (Louizos et al., 2018)> 같은 경우는 가장 처음 target network를 학습할 때부터 관련된 Network의 Sparsity와 관련된 Loss Term을 설정하여, 처음 네트워크를 학습함과 동시에 Pruning을 고려하는 모습을 보여주기도 합니다.
Weight Pruning의 가장 큰 장점은 그 압축 비율에 있습니다. 각각 가중치들이 제거될지 아닐지를 개별적으로 판단하기 때문에, 특정 구조 단위로 가중치들이 판별되는 structured pruning에 비해 일반적으로는 더 많은 가중치들이 제거될 수 있습니다. 다만 weight pruning의 가장 큰 단점은 pruning 결과가 sparse matrix로 나타난다는 점인데, 실제로 우리가 사용하는 PyTorch나 TensorFlow 라이브러리 상에서는 해당 sparse matrix로 추론하는 것이 실제로 이득으로 이어지지 않는다는 점이 뼈아픕니다. 따라서 보통 weight pruning은 실제 이용보다는 이론상의 neural network 구조에 대해 연구하는 목적이나, 혹은 실제로 이용한다면 FPGA 등 하드웨어적인 사항들이 추가적으로 언급되는 경우도 꽤나 많습니다.
Weight Pruning의 반대는 Structured Pruning입니다. 앞서 잠시 언급되었듯이 structured pruning은 convolution layer 가중치의 채널, 필터, 혹은 특정 구조의 그룹 단위로 제거되는 지의 여부를 판단하는 방법입니다. Structured pruning의 장단점은 weight pruning과 정확히 반대라고 보시면 됩니다. 비교적 그 압축 비율이 낮지만, 결과적으로 만들어진 모델의 architecture가 일반적인 라이브러리나 프레임워크와 완벽하게 호환이 가능하기 때문에, 실제 사용 용도로 pruning 연구들을 찾아보게 되면 structured pruning 쪽으로 접하게 되실 겁니다. 이 논문에서 다루고 있는 방법들 외에도 워낙 많은 방법들이 있기 때문에, 정확히 어떤 방법들이 개성을 뽐내고 있는지는 생략하도록 하겠습니다.
Methodology
위에서는 생략했지만, 논문의 Section 2에서는 굉장히 많은 pruning 사전 연구들을 언급하고 있습니다. 이 논문에서는 앞서 설명드렸던 가설들을 실제로 실험해 보기 위해, 이 많은 pruning 연구들 중 몇 가지의 대표적인 predefined pruning과 automatic pruning, 그리고 automatic pruning의 한 갈래로 unstructured pruning 기법들을 선정하여 CIFAR-10, CIFAR-100, 그리고 ImageNet에 대한 Image Classification 실험을 수행하였습니다.
이 논문에서 특별히 실험할 때 신경을 쓴 부분은 Training Budget에 관한 부분을 추가한 것입니다. Training Budget은 Pruning 후의 모델을 처음부터 새로 학습시킬 때 어느 정도의 epoch 동안 학습시켜야 하는지를 뜻합니다. 원래의 큰 모델을 학습시킬 때와 같은 epoch 동안 학습하면, 작은 모델의 경우 한 epoch에 더 적은 계산이 이루어지므로 공정하지 않다고 주장하고 있습니다. 따라서, 저자들은 pruned 모델과 원래의 모델의 FLOPs를 계산하고 비교하여, 결과적으로 두 모델의 학습 동안 이뤄지는 계산량이 동일하도록 pruned 모델의 epoch을 늘리도록 하며, 이를 Scratch-B라고 부르고 있습니다. 반대로 단순히 같은 epoch 동안 학습을 진행하는 것을 Scratch-E라고 부릅니다. 다만 ImageNet의 경우 만약 pruned model이 2배 이상의 FLOPs를 절감하게 되면, 즉 FLOPs가 반 이하로 떨어지게 되면 그냥 epoch 길이는 2배만 해 준다고 되어 있는데, 이는 ImageNet 모델의 경우 3배, 5배 같은 식으로 epoch이 길어지게 되면 실험 시간이 너무 길어지게 되고 실질적으로도 별 도움이 안 되기 때문이라고 유추해 볼 수 있습니다.
여기서 잠깐 생각할 수 있는 것이 “그냥 수렴할 때까지 학습시키면 안 되나?”라는 것이지만, 저자들은 현재 full convergence로 학습하는 방법이 굉장히 경험적이고 확실한 방법이 아니(unclear 하다)라고 말하고 있습니다.
또한 생각해 볼 수 있는 주장은 “작은 모델은 더 빨리 수렴하니까 더 적은 epoch으로 학습시켜야 하는 것 아닌가?”라는 질문입니다. 여기에 대해서 저자들은 적당한 선에서 training epoch을 늘리는 것은 그렇게 학습에 해가 되지 않는다고 말하고 있습니다. 실제 실험 결과, 보통은 Scratch-E로 충분하나 fine-tuning 후의 정확도 선으로 좋은 결과를 얻기 위해서는 오히려 Scratch-B가 이루어져야 한다고 하며, 이런 결과들을 바탕으로 Scratch-E와 Scratch-B의 접근법에 대한 정당성을 제시합니다.
1편을 마치며
자, 이제 우리가 살펴보고 있는 논문, <Rethinking the Value of Network Pruning>의 이론적인 부분들을 모두 살펴보았습니다. 위와 같은 방법으로 저자는 여러 pruning 방법들에 대해 초기화 실험을 진행했습니다. 이어지는 2편에서는 해당 pruning 방법들에 대한 좀 더 자세한 설명과 함께, 실험 내용과 결과들에 대해 소개해 드리도록 하겠습니다.
 mAy-I(메이아이)
mAy-I(메이아이)