

안녕하세요, 메이아이의 Lead Engineer 신인식입니다.
메이아이는 공간에 설치되어 있는 CCTV의 영상을 활용하여, 영상 처리 인공지능으로 방문객들의 성별이나 연령대부터 동선, 체류 시간, 행동, 상품과의 인터랙션까지 모든 데이터를 분석하고 있습니다.
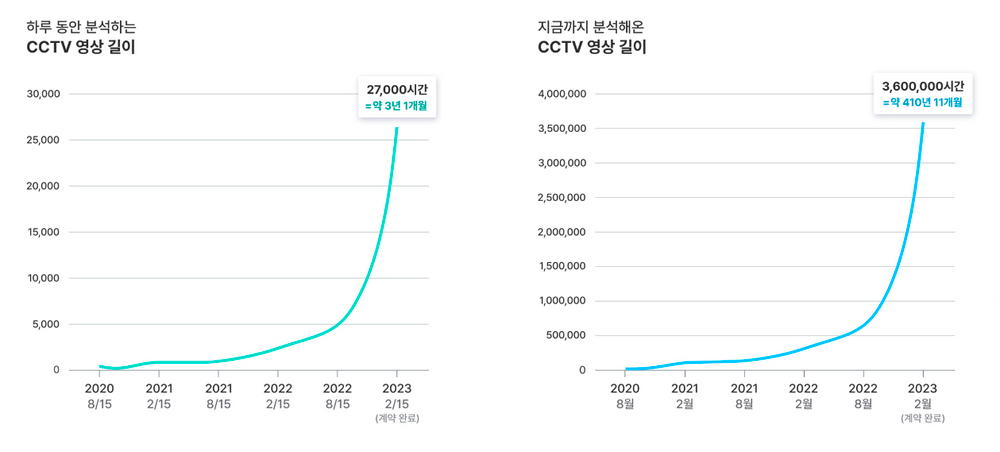
상당한 양의 영상 데이터를 분석하고 있고 앞으로 더 많은 양을 분석할 예정인 만큼, 영상 분석 파이프라인이야말로 매우 중요한 구성 요소 중 하나라고 할 수 있는데요. 그래서 이번 글을 통해 단일 영상 분석 파이프라인이 어떻게 구성되어 있는지를 소개해 보고자 합니다.
요구사항 및 워크플로우 명세
메이아이의 인공지능 분석 엔진 'daram'을 사용하여 영상 파일 한 개를 분석하는 워크플로우를 실행
- 영상 파일의 메타데이터(S3 경로, 길이 등을 담고 있음)
- 분석 설정
- Data Lake(S3)에 daram으로 분석한 결과를 저장
- Data Lake에 저장된 여러 raw data를 가공하여 Data Warehouse(DynamoDB)에 저장
추가로, 단일 워크플로우가 비대해지는 문제를 방지하기 위해 파일 하나의 길이는 30분을 넘기지 않는다는 약한 정책을 가지고 있습니다. 수집되는 영상 스트림의 길이가 30분보다 길 때는 30분 단위로 나누어 저장합니다. 이 요구사항에 맞춰 설계한 아키텍처는 다음과 같습니다.
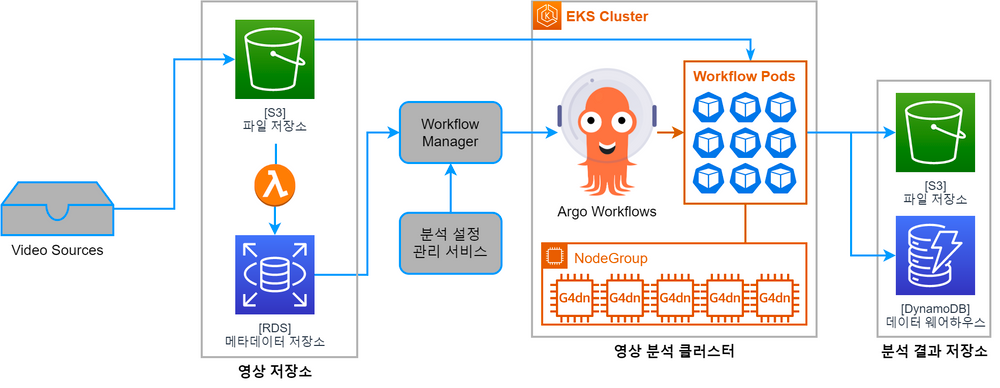
영상 저장소 및 워크플로우 관리
여러 경로를 통해 수집된 영상 파일은 모두 S3에 저장되고, 해당 파일들의 메타데이터는 RDS에 있는 메타데이터 저장소에 보관됩니다.
워크플로우 엔진으로는 Argo Workflows를, 워크플로우 관리를 위해서는 별도의 Workflow Manager 서비스를 사용하고 있습니다. Workflow Manager 서비스는 비즈니스 로직을 반영하기 위해 자체 개발한 파이썬 애플리케이션입니다. 정해진 주기마다 메타데이터 저장소에 새로운 영상 파일 메타데이터가 존재하는지 확인하고, 분석 설정 관리 서비스에서 분석 설정을 불러와 워크플로우 엔진에 새로운 워크플로우를 등록합니다.
워크플로우의 메타데이터 또한 메타데이터 저장소에 보관됩니다. 어떤 영상 파일을 분석하는지, 워크플로우의 상태는 어떤지를 확인하기 위해 사용합니다. Argo Workflows의 워크플로우 DB 대신 별도의 메타데이터 DB를 운용하는 이유는, 영상 메타데이터와 JOIN해서 사용하기 위함입니다.
워크플로우 구성
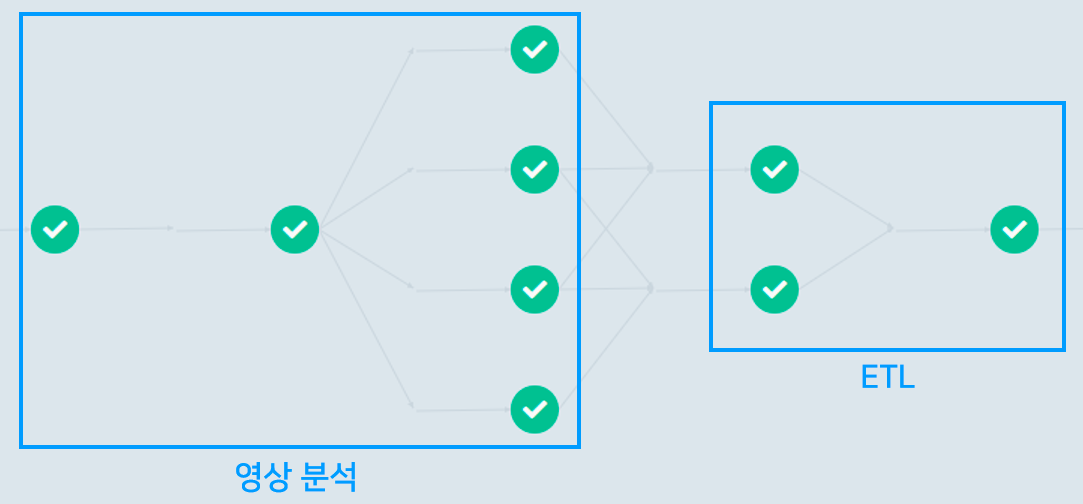
워크플로우에는 일반적으로 두 가지 워크로드가 포함되어 있습니다.
- 영상 분석: daram을 사용하여 영상을 분석하고, 그 결과를 Data Lake(S3)에 저장
- ETL: Data Lake에 저장된 분석 결과를 가공하여 Data Warehouse (DynamoDB)에 저장
위의 예시는 모든 스텝을 포함한 경우를 시각화한 것이고, 실제 운영 상황에서는 니즈에 따라 일부 스텝만 정의된 워크플로우를 실행하기도 합니다.
오류 대응
당연히 워크플로우가 실행 도중 실패하는 경우도 있습니다. 그럴 때는 이러한 순서로 대응합니다.
- 워크플로우에 정의된 exit handler가 메타데이터 저장소에 있는 워크플로우 메타데이터의 상태를 FAILED로 변경합니다.
- 이를 확인한 Workflow Manager는 해당 문제가 영향을 끼칠 수 있는 범위에 한하여 신규 워크플로우 등록을 중단합니다. 대개는 분석 설정의 오류이므로, 동일한 분석 설정을 공유하는 같은 공간의 카메라로부터 수집된 영상들이 격리 범위가 됩니다.
- 메인 대시보드에 실패 내역이 표시되고, 엔지니어가 이를 확인하여 대응합니다.
- 워크플로우 메타데이터의 상태를 PENDING으로 변경하고 다시 실행합니다.
선택의 이유들
EKS
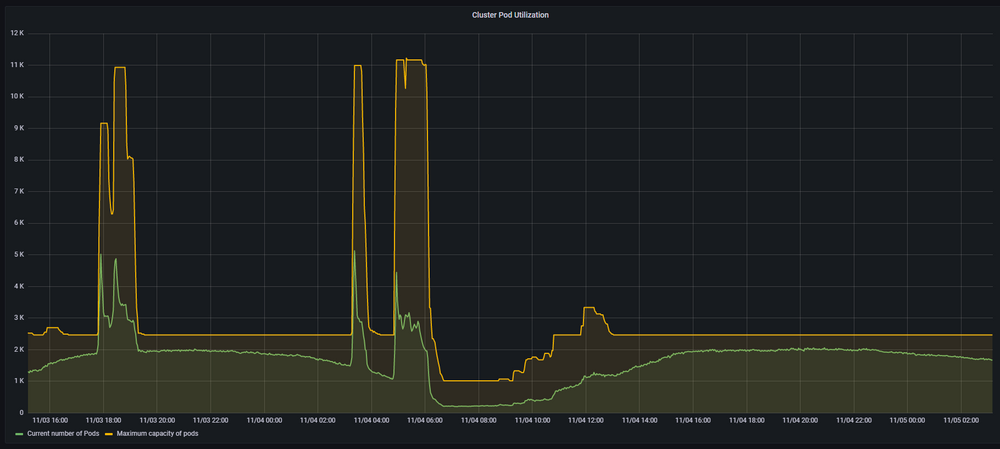
Argo Workflows 서비스는 Kubernetes 클러스터 상에서 실행되고 있습니다. 워크플로우를 실행하면 해당 클러스터에 Pod를 생성하여 처리합니다. 따라서 Pod의 개수가 워크플로우의 개수에 비례합니다.
처음에는 kops로 직접 클러스터를 구축하여 관리했는데, 워크플로우의 수가 많아짐에 따라 마스터 노드에 가해지는 부하와 etcd 데이터베이스의 용량 문제 등으로 인해 유지 보수에 많은 시간을 쓰기 시작했습니다. 하루에 분석하는 영상이 고작 2천 시간 수준일 때 겪은 문제였습니다.
따라서 control plane을 관리하는 데 드는 리소스를 제거하기 위해, kops로 구축된 클러스터를 EKS 환경으로 마이그레이션했습니다. 사실 EKS 환경에서도 control plane이 충분히 빠르게 scale out 되지 못하는 문제가 있었습니다. 하지만 EKS 팀에서 이 문제를 개선하는 작업을 완료했고, 지금은 아주 만족하며 사용하고 있습니다.
Argo Workflows
Argo Workflows의 워크플로우는 기본적으로 YAML 형태로 정의됩니다. DAG를 코드로 작성하는 대신 YAML으로 작성할 수 있다는 이점이 있습니다.
위에서 언급한 바와 같이 일부 스텝만 정의해야 하는 경우에도 YAML 템플릿 중에서 단 하나만 선택해도 되니 편리할 뿐 아니라 수동으로 커스터마이즈 해야 하는 경우에도 실수를 최소화할 수 있다는 이점들이 있습니다. 무엇보다 파일 형태가 YAML이므로 템플릿의 형상 관리도 간편합니다. 다음은 workflow를 YAML로 정의한 예시와, 이를 시각화한 이미지입니다.

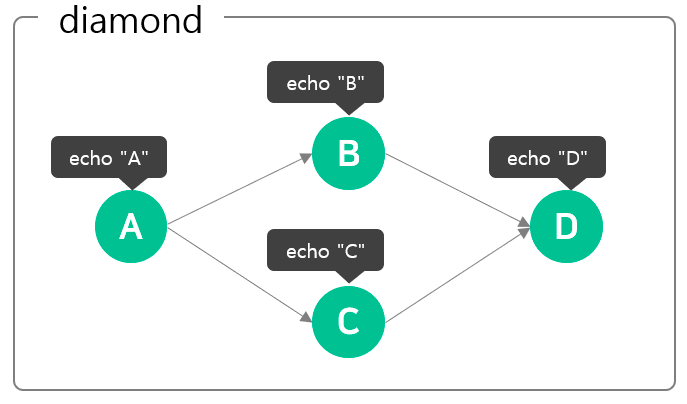
만약 굉장히 친화적인 Kubernetes 시스템의 생태계 경험이 단 한 번이라도 있다면, 러닝 커브를 더욱 가파르게 만들 수 있다는 점은 매우 큰 장점이 될 수 있습니다. 어차피 컴퓨팅 자원을 관리하기 위해서는 Kubernetes를 사용하게 될 테니까요. Kubeflow가 내부적으로 Argo Workflows를 사용하고 있다는 점 또한 긍정적이었습니다.
DynamoDB
Schemaless
데이터 웨어하우스에 업로드되는 데이터는 모두 '이벤트'로 정의되고 있습니다. 비즈니스 요구를 충족하기 위해서는 이벤트 스키마가 유연할 필요가 있었습니다.
매니지드 서비스
메이아이 팀에는 문제를 해결해 줄 수 있는 매니지드 서비스가 존재한다면 최대한 활용한다는 철학이 흐르고 있습니다. 충분히 성숙한 서비스가 있다면 더욱더 권장하는데, DynamoDB 또한 그런 선택이었습니다. 관리 리소스는 물론이고, DynamoDB Streams와 같은 기능을 활용하면 개발 리소스까지 줄일 수 있기 때문에 이 측면에서는 굉장히 만족하고 있습니다.
접근성
웹 콘솔을 통해서 데이터를 쿼리 할 수 있기 때문에, 간단한 질의에 대해서는 비 개발 직군에 계신 분들도 쉽게 raw data를 확인할 수 있다는 장점 또한 존재합니다. 다만, pagination을 통해서만 데이터를 불러올 수 있기 때문에 대량의 데이터를 한 번에 확인하려면 AWS SDK를 활용하는 코드를 작성해야 한다는 단점이 있습니다. 그러나 기술적인 제약 사항이 몇 가지 있고, 실제로 이로 인해 제약을 받고 있습니다.
- item size에 hard limit이 있음 : 400KB
- 완전한 NoSQL 컨셉을 구현하고 있으므로 SQL로 질의할 수 없고, SDK를 사용하는 코드를 작성해야 하므로 비개발 직군은 복잡한 질의를 수행하기 어려움
비 개발 직군의 접근성을 개선하고, 기술적 제약을 해소하기 위해 schemaless함에 대한 타협과 BigQuery 또는 Snowflake 등으로의 전환에 열려 있는 상태입니다.
Challenges
Scalability
Argo Workflows의 워크플로우 등록 속도에 upper bound가 존재하는 것으로 관찰됩니다. 이 문제는 하루에 분석할 수 있는 영상 길이에 직접적으로 영향을 미칩니다. 실제로 throughput에 한계가 존재하는지, 또는 설정이나 트윅으로 해결될 수 있는 문제인 지 등에 대해 더 자세히 조사하여 액션 할 필요가 있습니다. 이러한 문제처럼, capability에 영향을 끼치는 모든 문제를 찾아 우선순위를 매기고 해결해야 합니다.
Optimization
AWS 환경에서는 대량의 GPU 인스턴스를 사용하고 있습니다. 그러나 최근 수년간 GPU 인스턴스를 수급하는 일은 매우 어려운 상황입니다. 따라서 워크플로우 관리 과정에서 발생하는 오버헤드와, 워크플로우 내부 스텝을 수행하는 데 드는 시간을 최소화하여 같은 GPU 수로 더 많은 영상을 분석하도록 할 필요가 있습니다.
IaC(Infrasturcture as Code)
인프라 구성과 설정에 대한 맥락을 보존하기 위해서는 IaC를 부분적으로 도입해 보았습니다. 그 결과 테스트 환경을 쉽게 생성할 수 있다는 이점을 몸소 체감하고 있습니다. 다만, 현재는 EKS 클러스터와 그 하위 구성만 terraform으로 작성된 상태이므로 S3 버킷과 수명 주기 등의 AWS 리소스들도 terraform으로 작성할 필요가 있습니다.
분석 설정 관리 서비스
분석 설정을 관리하는 주체는 고객과 CSM(Customer Success Manager)입니다. 이런 유저들이 수행하는 작업들도 상당히 복잡한 편인데요. 그렇기에 분석 설정 관리 서비스가 유저들의 생산성에 큰 영향을 미칩니다. 유저들의 태스크를 분석하여 워크플로우를 정의하고, 이를 최대한 자동화하여 보조하도록 서비스를 고도화할 필요가 있습니다.
마치며
지금까지 쭉 '단일 영상 분석 파이프라인'이라는 표현을 사용해 왔는데요. 그렇다면 '복수 영상 분석 파이프라인'도 있다는 의미일까요?
그렇습니다. 메이아이의 인공지능 분석 엔진으로는 단일 영상을 분석하는 daram 말고도, 복수 영상을 분석하는 boram이 존재합니다. 다음 글에서는 boram을 사용하는 분석 파이프라인에 대해서 다뤄보도록 하겠습니다. 끝까지 읽어주셔서 감사합니다.








